前言
这篇论文CARAFE: Content-Aware ReAssembly of FEatures被 ICCV 2019 接收为 oral presentation。它致力于解决一些通用模块和算子的问题。上采样操作是各种网络结构里广泛使用的运算之一,这篇文章提出了一个轻量级的通用上采样算子 CARAFE(音[kə’ræf]),相对最近邻和双线性等上采样算子,在不同任务中都取得了显著的提升,同时只引入很少的参数量和计算代价。

背景知识
上采样操作可以表示为每个位置的上采样核和输入特征图中对应邻域的像素做点积,我们称之为特征重组。论文提出的上采样操作 CARAFE 在重组时可以有较大的感受野,会根据输入特征语义信息来指导重组过程,同时整个算子比较轻量级。具体来说,文章首先利用输入特征图来预测上采样核,每个位置的上采样核是不同的,然后基于预测的上采样核来进行特征重组。在不同的任务中,CARAFE 都取得了明显的提升,同时仅带来很小的额外参数和计算量。
上采样的表示
将特征图的上采样运算看做是特征重组的过程。对于输出特征图中的每个像素点 L’,我们都可以找到它在输入特征图中的对应位置 L,L’ 这个点的值可以表示成以输入特征图中以 L 为中心的一个邻域内的像素和一个上采样核的点积(加权和)。以双线性上采样为例,输出特征图中每个像素可以看作是一个 2x2 的上采样核和输入特征图中一个 2x2 的邻域的点积。在下图中,上采样核的 4 个数值均为 0.5。
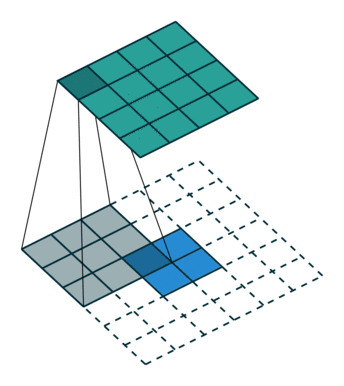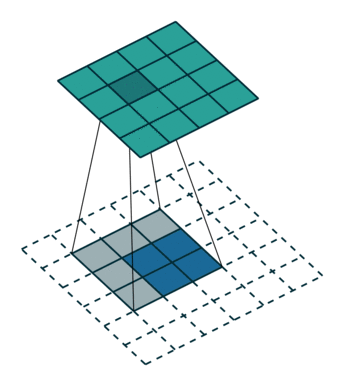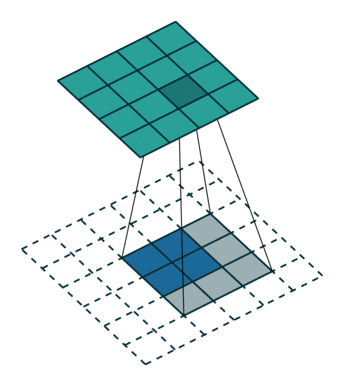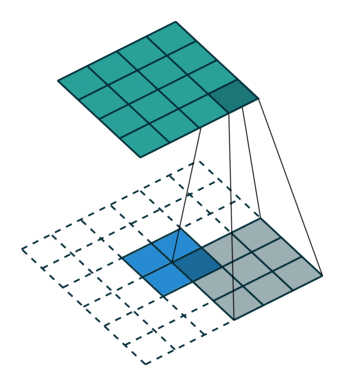
value 是输入的特征图:
将这个特征图进行上采样,格式是[n,h,w,c],n是你这一个batch的图片数量,
h和w是特征图的宽和高,c是特征图的数量;
filter是卷积核的大小:
四维的[h,w,in_channel,out_channel],h和w是卷积核的大小,
in_channel是输入特征图的数量,out_channel是输出特征图的数量。
output_shape: 是要上采样得到的特征图的大小,格式与value一致。
strides是步长: 四维格式,分别对应value四个维度的步长。 Motivation
最近邻或者双线性上采样: 仅通过像素点的空间位置来决定上采样核,并没有利用到特征图的语义信息,可以看作是一种“均匀”的上采样,而且感知域通常都很小(最近邻 1x1,双线性 2x2)。
Deconvolution(反卷积)算子的上采样核: 并不是通过像素间的距离计算,而是通过网络学出来的,但对于特征图每个位置都是应用相同的上采样核,不能捕捉到特征图内容的信息,另外引入了大量参数和计算量,尤其是当上采样核尺寸较大的时候。
Dynamic filter: 对于特征图每个位置都会预测一组不同的上采样核,但是参数量和计算量更加爆炸,而且公认比较难学习。
那么本文所希望的上采样算子应该具备以下几个特性:
- Large receptive field:需要具有较大的感受野,这样才能更好地利用周围的信息。
- Content-aware:上采样核应该和特征图的语义信息相关,基于输入内容进行上采样。
- Lightweight:不能引入过多的参数和计算量,需要保持轻量化。
整体框架
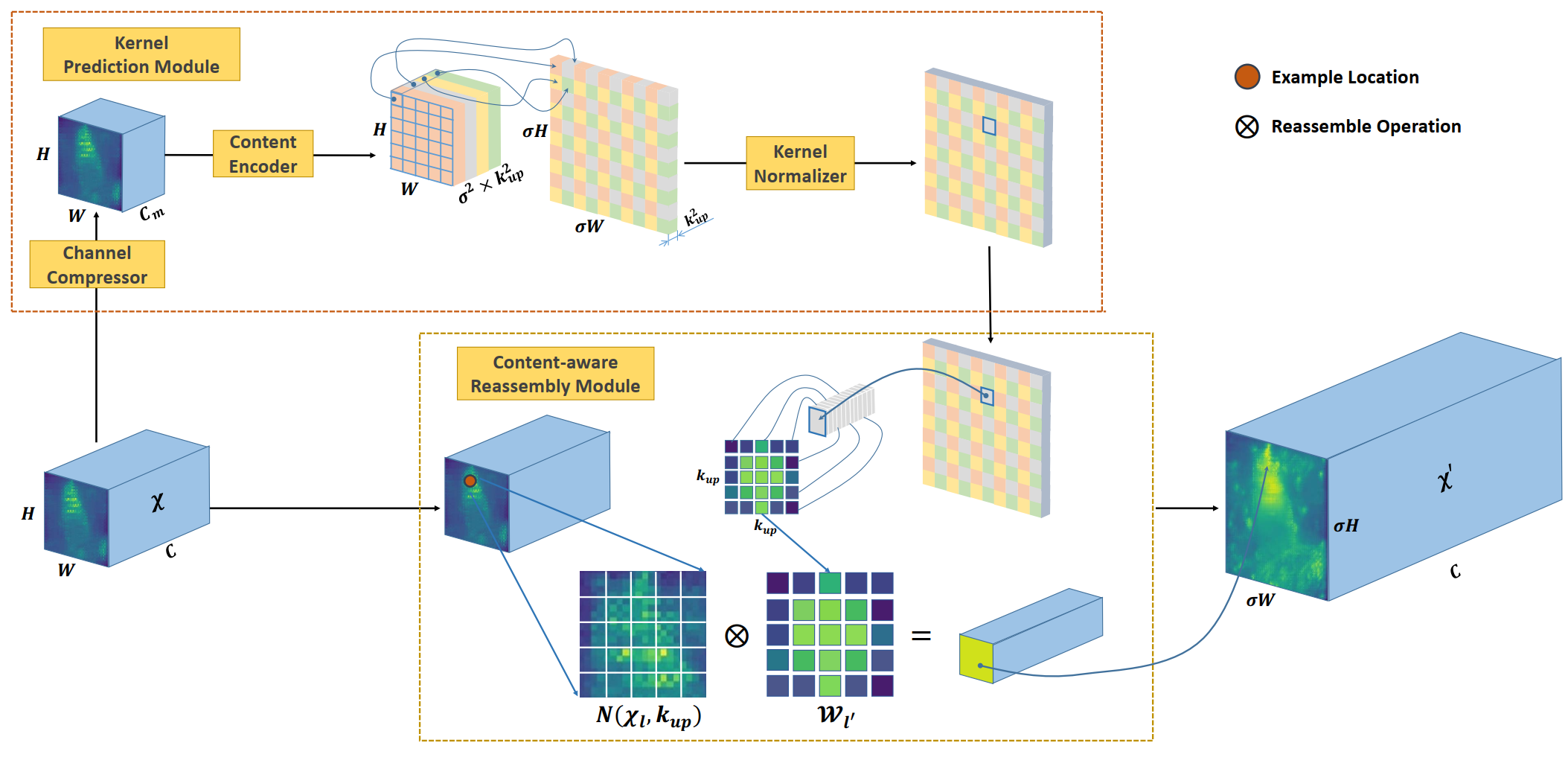
CARAFE 分为两个主要模块,分别是上采样核预测模块和特征重组模块。假设上采样倍率为 [公式] ,给定一个形状为 [公式] 的输入特征图,首先利用上采样核预测模块预测上采样核,然后利用特征重组模块完成上采样,得到形状为 [公式] 的输出特征图。
上采样核预测模块

- 特征图通道压缩
对于形状为 [公式] 的输入特征图,我们首先用一个 [公式] 卷积将它的通道数压缩到 [公式] ,这一步的主要目的是减小后续步骤的计算量。
- 内容编码及上采样核预测
假设上采样核尺寸为 [公式] (越大的上采样核意味着更大的感受野和更大的计算量),如果我们希望对输出特征图的每个位置使用不同的上采样核,那么我们需要预测的上采样核形状为 [公式] 。
对于第一步中压缩后的输入特征图,我们利用一个 [公式] 的卷积层来预测上采样核,输入通道数为 [公式] ,输出通道数为 [公式] ,然后我们将通道维在空间维展开,得到形状为 [公式] 的上采样核。
- 上采样核归一化
对第二步中得到的上采样核利用 softmax 进行归一化,使得卷积核权重和为 1。
特征重组模块
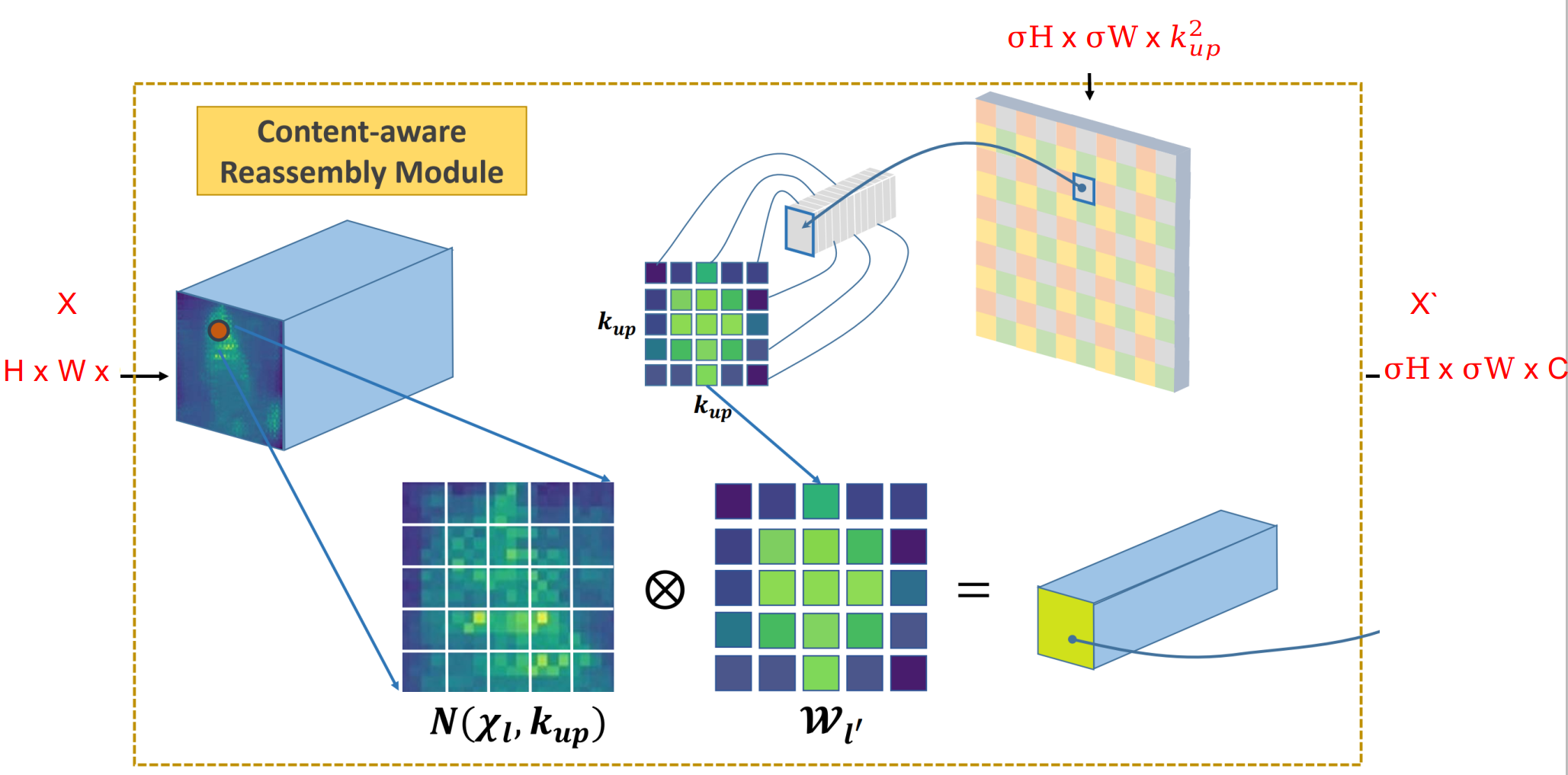
对于输出特征图中的每个位置,我们将其映射回输入特征图,取出以之为中心的 [公式] 的区域,和预测出的该点的上采样核作点积,得到输出值。相同位置的不同通道共享同一个上采样核。
实验结果
论文将 FPN 中的上采样操作替换成 CARAFE,并可视化上采样的区域和权重。对于高层特征图中不同的点,我们展示在 CARAFE 多次上采样后的采样核权重较大的点,可以看到采样点会集中在物体区域而忽略背景区域,达到 content-aware 的效果。
以 Faster R-CNN w/ FPN 为例,本文对比了 CARAFE 和其他上采样算子的性能以及参数量和计算量。在性能明显优于其他算子的情况下,CARAFE 保持了轻量级的特性,参数量和计算量都较小。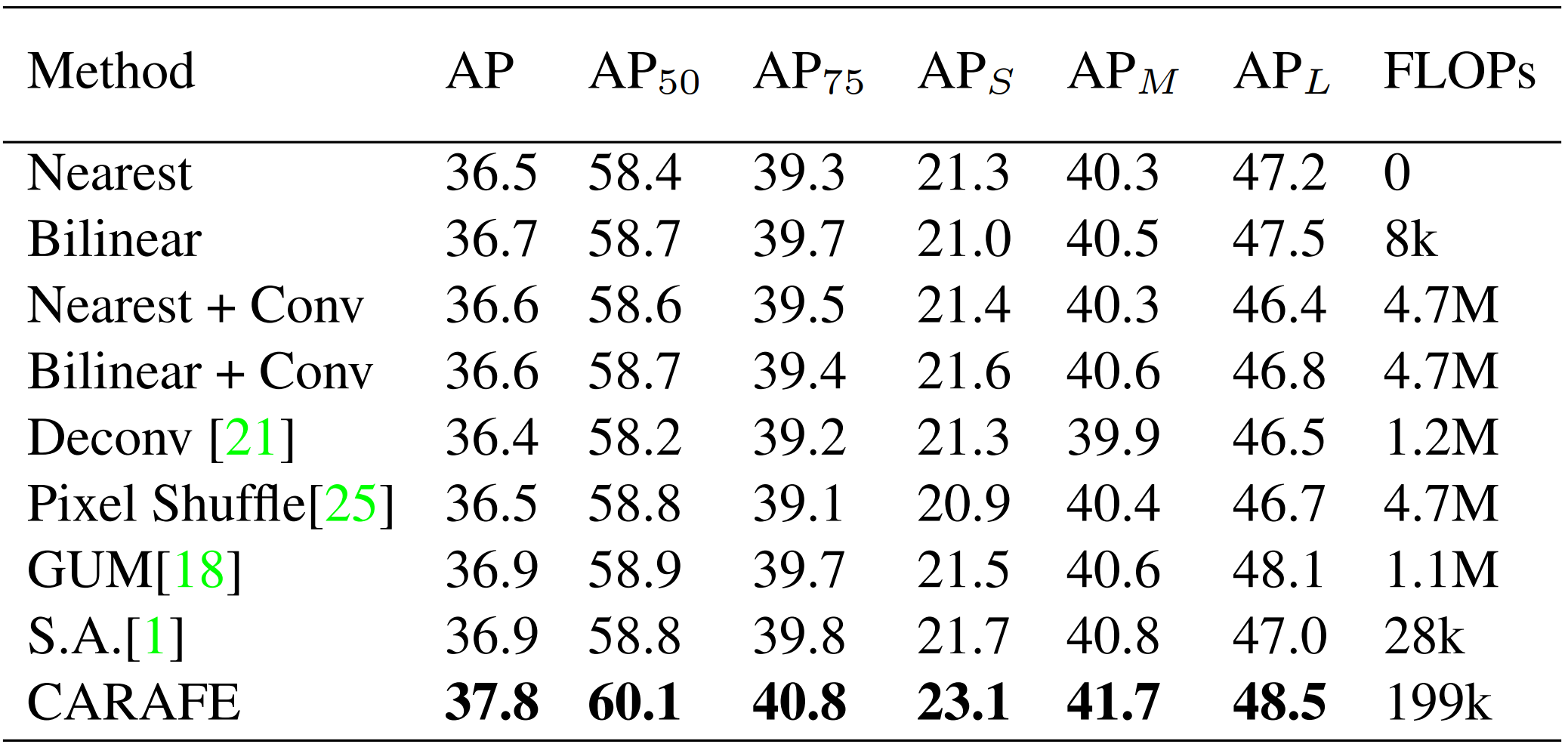
同事本文将 CARAFE 应用于不同的任务中,例如物体检测,语义分割,image inpainting ,都取得了不错的效果。
物体检测
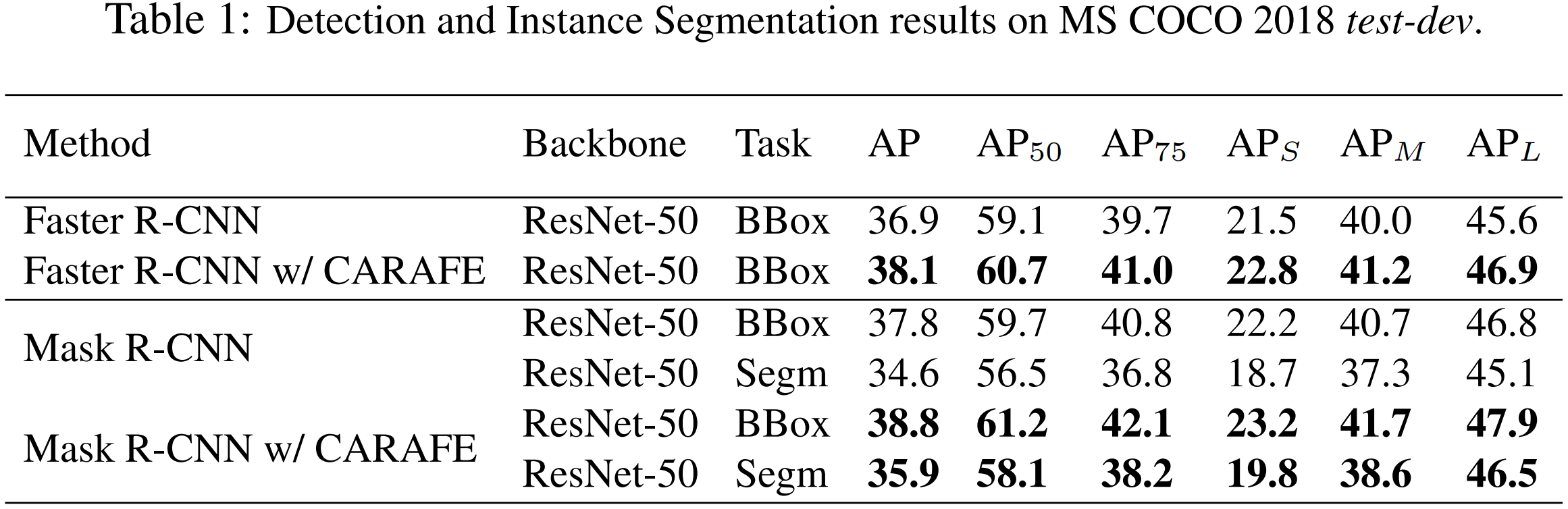
在物体检测任务上,对于 Faster R-CNN 和 Mask R-CNN,CARAFE 都取得了一个点以上的提升。
语义分割

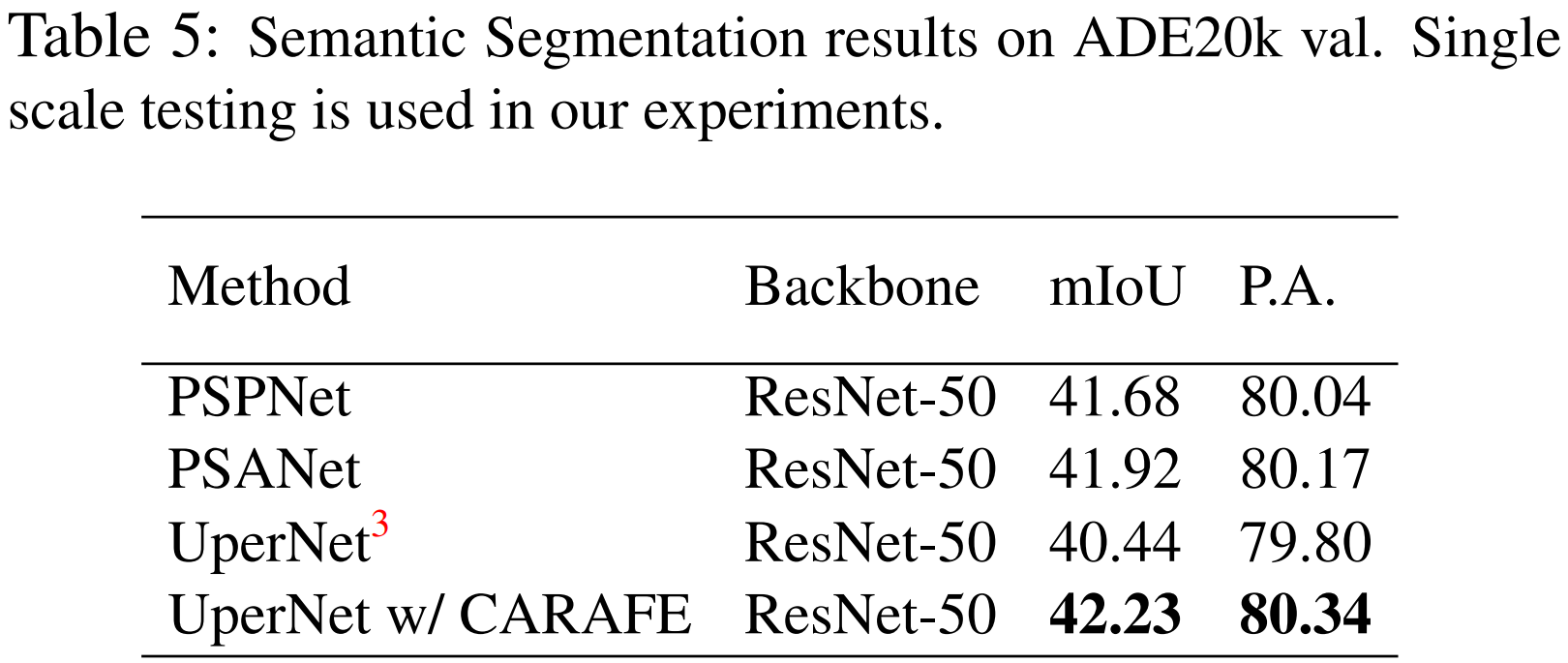
在语义分割任务中,我们将 UperNet(为啥用 UperNet,因为有好用的开源 code 啊)作为 baseline,用 CARAFE 替换其中的上采样操作,取得了显著的提升。
Image inpainting
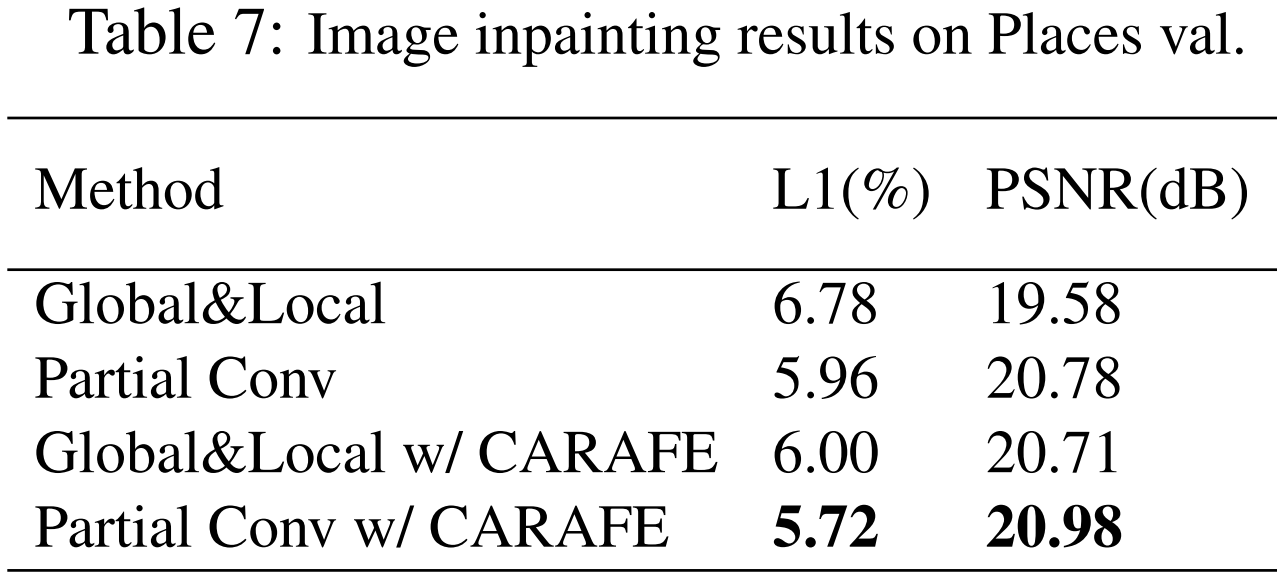
我们也尝试把 CARAFE 应用在 low-level 任务比如 image inpainting 中,同样取得了较大的提升,刷新了 SOTA。
etc.
总结
文章提出的轻量级通用上采样算子:
- Large receptive field
- Content-aware
- Lightweight



